Introduction
TAT-QA (Tabular And Textual dataset for Question Answering) is a large-scale QA dataset, aiming to stimulate progress of QA research over more complex and realistic tabular and textual data, especially those requiring numerical reasoning.
The unique features of TAT-QA include:
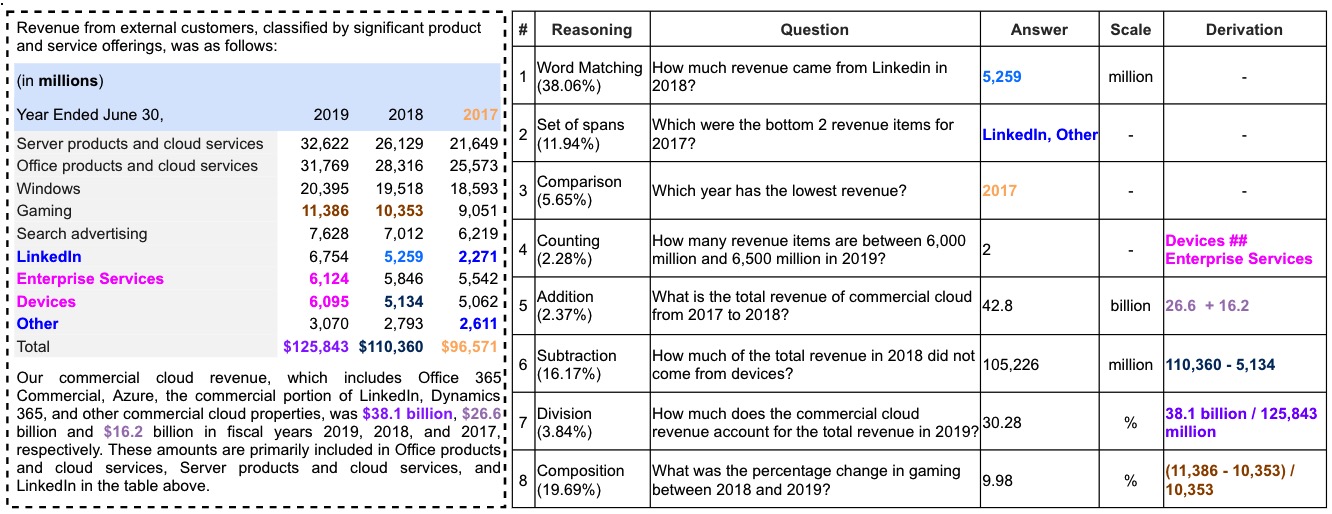
- The context given is hybrid, comprising a semi-structured table and at least two relevant paragraphs that describe, analyze or complement the table;
- The questions are generated by the humans with rich financial knowledge, most are practical;
- The answer forms are diverse, including single span, multiple spans and free-form;
- To answer the questions, various numerical reasoning capabilities are usually required, including addition (+), subtraction (-), multiplication (x), division (/), counting, comparison, sorting, and their compositions;
- In addition to the ground-truth answers, the corresponding derivations and scale are also provided if any.
In total, TAT-QA contains 16,552 questions associated with 2,757 hybrid contexts from real-world financial reports.
The following is an example of TAT-QA. The left dashed line box shows a hybrid context. The rows with blue background are row header while the column with grey is column header. The right solid line box shows corresponding question, answer with its scale, and derivation to arrive at the answer.
For more information, please read our ACL 2021 paper [PDF].
TAT-DQA is a new large-scale Document Visual QA (VQA) dataset, which is constructed by extending the TAT-QA. Please check out it if you are interested in the new task.